導讀 當我們交友平台在線上運行一段時間後,為了給平台用戶在搜索好友時,在搜索結果中推薦并置頂他感興趣的好友,這時候,我們會對用戶的行為做數據分析,根據分析結果給他推薦其感興趣的好友。
這裡,我采用最簡單的SQL分析法:對用戶過去查看好友的性别和年齡進行統計,按照年齡進行分組得到統計結果。依據該結果,給用戶推薦基數最高的某個性别及年齡的好友。
那麼,假設我們現在有一張用戶浏覽好友記錄的明細表t_user_view,該表的表結構如下:
CREATE TABLE `t_user_view` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 自增id, `user_id` bigint(20) DEFAULT NULL COMMENT 用戶id, `viewed_user_id` bigint(20) DEFAULT NULL COMMENT 被查看用戶id, `viewed_user_sex` tinyint(1) DEFAULT NULL COMMENT 被查看用戶性别, `viewed_user_age` int(5) DEFAULT NULL COMMENT 被查看用戶年齡, `create_time` datetime(3) DEFAULT CURRENT_TIMESTAMP(3), `update_time` datetime(3) DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3), PRIMARY KEY (`id`), UNIQUE KEY `idx_user_viewed_user` (`user_id`,`viewed_user_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; 複制代碼
為了方便使用SQL統計,見上面的表結構,我冗餘了被查看用戶的性别和年齡字段。
我們再來看看這張表裡的記錄:
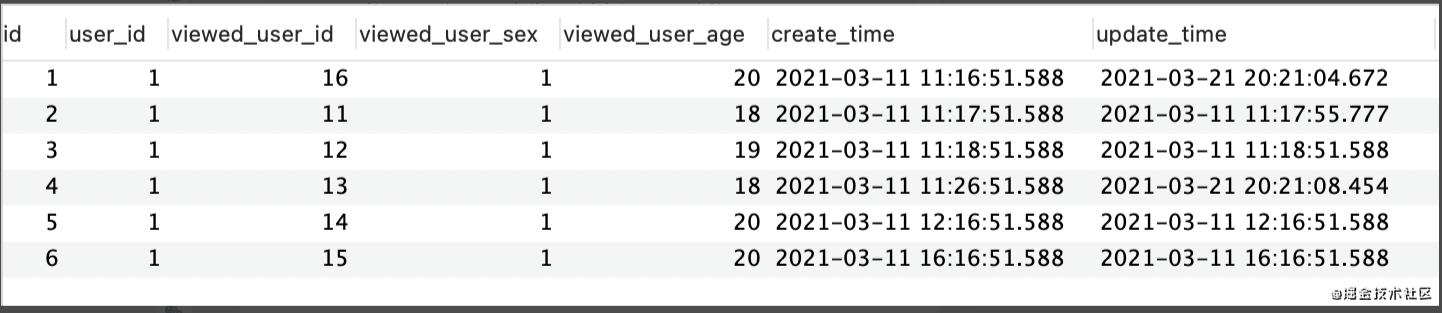
現在結合上面的表結構和表記錄,我以user_id=1的用戶為例,分組統計該用戶查看的年齡在18 ~ 22之間的女性用戶的數量:
SELECT viewed_user_age as age, count(*) as num FROM t_user_view WHERE user_id = 1 AND viewed_user_age BETWEEN 18 AND 22 AND viewed_user_sex = 1 GROUP BY viewed_user_age 複制代碼
得到的統計結果如下:

可見:
該用戶查看年齡為18的女性用戶數為2該用戶查看年齡為19的女性用戶數為1該用戶查看年齡為20的女性用戶數為3 所以,user_id=1的用戶對年齡為20的女性用戶更感興趣,可以更多推薦20歲的女性用戶給他。
如果此時,t_user_view這張表的記錄數達到千萬規模,想必這條SQL的查詢效率會直線下降,為什麼呢?有什麼辦法優化呢?
想要知道原因,不得不先看一下這條SQL執行的過程是怎樣的?
explain 我們先用explain看一下這條SQL:
EXPLAIN SELECT viewed_user_age as age, count(*) as num FROM t_user_view WHERE user_id = 1 AND viewed_user_age BETWEEN 18 AND 22 AND viewed_user_sex = 1 GROUP BY viewed_user_age 複制代碼
執行完上面的explain語句,我們得到如下結果:

在Extra這一列中出現了三個Using,這3個Using代表了《導讀》中的groupBy語句分别經曆了3個執行階段:
Using where:通過搜索可能的idx_user_viewed_user索引樹定位到滿足部分條件的viewed_user_id,然後,回表繼續查找滿足其他條件的記錄Using temporary:使用臨時表暫存待groupBy分組及統計字段信息Using filesort:使用sort_buffer對分組字段進行排序 這3個階段中出現了一個名詞:臨時表。這個名詞我在《MySQL分表時機:100w?300w?500w?都對也都不對!》一文中有講到,這是MySQL連接線程可以獨立訪問和處理的内存區域,那麼,這個臨時表長什麼樣呢?
下面我就先講講這張MySQL的臨時表,然後,結合上面提到的3個階段,詳細講解《導讀》中SQL的執行過程。
臨時表 我們還是先看看《導讀》中的這條包含groupBy語句的SQL,其中包含一個分組字段viewed_user_age和一個統計字段count(*),這兩個字段是這條SQL中統計所需的部分,如果我們要做這樣一個統計和分組,并把結果固化下來,肯定是需要一個内存或磁盤區域落下第一次統計的結果,然後,以這個結果做下一次的統計,因此,像這種存儲中間結果,并以此結果做進一步處理的區域,MySQL叫它臨時表。
剛剛提到既可以将中間結果落在内存,也可以将這個結果落在磁盤,因此,在MySQL中就出現了兩種臨時表:内存臨時表和磁盤臨時表。
内存臨時表 什麼是内存臨時表?在早期數據量不是很大的時候,以存儲分組及統計字段為例,那麼,基本上内存就可以完全存放下分組及統計字段對應的所有值,這個存放大小由tmp_table_size參數決定。這時候,這個存放值的内存區域,MySQL就叫它内存臨時表。
此時,或許你已經覺得MySQL将中間結果存放在内存臨時表,性能已經有了保障,但是,在《MySQL分表時機:100w?300w?500w?都對也都不對!》中,我提到過内存頻繁的存取會産生碎片,為此,MySQL設計了一套新的内存分配和釋放機制,可以減少甚至避免臨時表内存碎片,提升内存臨時表的利用率。
此時,你可能會想,在《為什麼我調大了sort_buffer_size,并發量一大,查詢排序慢成狗?》一文中,我講了用戶态的内存分配器:ptmalloc和tcmalloc,無論是哪個分配器,它的作用就是避免用戶進程頻繁向Linux内核申請内存空間,造成CPU在用戶态和内核态之間頻繁切換,從而影響内存存取的效率。用它們就可以解決内存利用率的問題,為什麼MySQL還要自己搞一套?
或許MySQL的作者覺得無論哪個内存分配器,它的實現都過于複雜,這些複雜性會影響MySQL對于内存處理的性能,因此,MySQL自身又實現了一套内存分配機制:MEM_ROOT。它的内存處理機制相對比較簡單,内存臨時表的分配就是采用這樣一種方式。
下面,我就以《導讀》中的SQL為例,詳細講解一下分組統計是如何使用MEM_ROOT内存分配和釋放機制的?
MEM_ROOT 我們先看看MEM_ROOT的結構,MEM_ROOT設計比較簡單,主要包含這幾部分,如下圖:
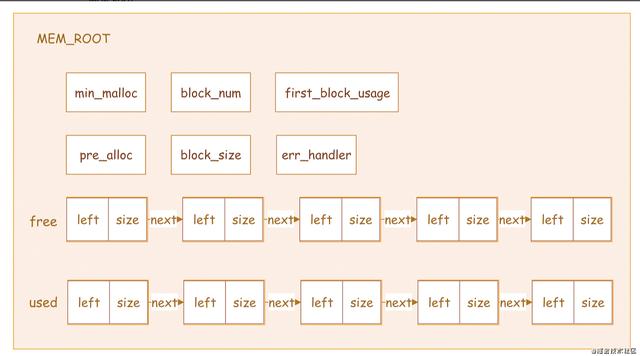
free:一個單向鍊表,鍊表中每一個單元叫block,block中存放的是空閑的内存區,每個block包含3個元素:
left:block中剩餘的内存大小size:block對應内存的大小next:指向下一個block的指針 如上圖,free所在的行就是一個free鍊表,鍊表中每個箭頭相連的部分就是block,block中有left和 size,每個block之間的箭頭就是next指針
used:一個單向鍊表,鍊表中每一個單元叫block,block中存放已使用的内存區,同樣,每個block包含上面3 個元素
min_malloc:控制一個 block 剩餘空間還有多少的時候從free鍊表移除,加入到used鍊表中
block_size:block對應内存的大小
block_num:MEM_ROOT 管理的block數量
first_block_usage:free鍊表中第一個block不滿足申請空間大小的次數
pre_alloc:當釋放整個MEM_ROOT的時候可以通過參數控制,選擇保留pre_alloc指向的block
下面我就以《導讀》中的分組統計SQL為例,看一下MEM_ROOT是如何分配内存的?
分配 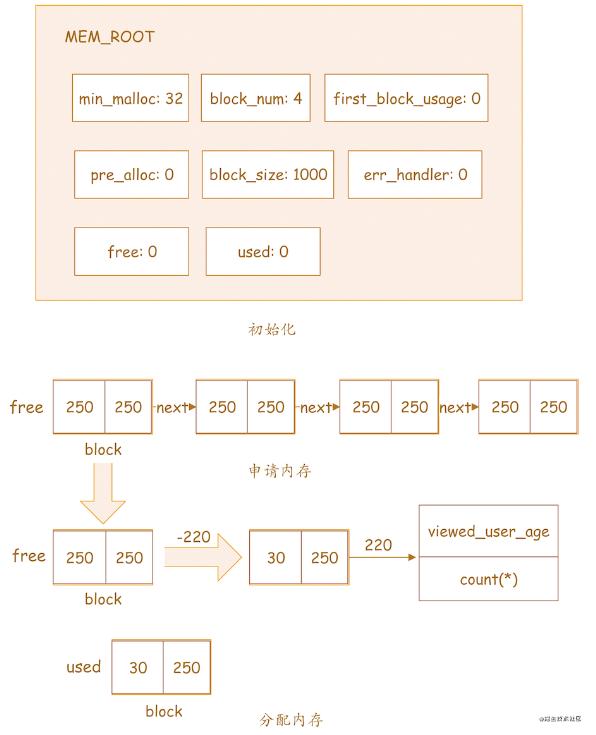
初始化MEM_ROOT,見上圖: min_malloc = 32 block_num = 4 first_block_usage = 0 pre_alloc = 0 block_size = 1000 err_handler = 0 free = 0 used = 0申請内存,見上圖: 由于初始化MEM_ROOT時,free = 0,說明free鍊表不存在,故向Linux内核申請4個大小為1000/4=250的block,構造一個free鍊表,如上圖,鍊表中包含4個block ,結合前面free鍊表結構的說明,每個block中size為250,left也為250分配内存,見上圖: (1) 遍曆free鍊表,從free鍊表頭部取出第一個block,如上圖向下的箭頭 (2) 從取出的block中劃分220大小的内存區,如上圖向右的箭頭上面-220,block中的left從250變成30 (3) 将劃分的220大小的内存區分配給SQL中的groupby字段viewed_user_age和統計字段count(*),用于後面的統計分組數據收集到該内存區 (4) 由于第(2)步中,分配後的block中的left變成30,30 32,即小于第(1)步中初始化的min_malloc,所以,結合上面min_malloc的含義的講解,該block将插入used鍊表尾部,如上圖底部,由于used鍊表在第(1)步初始化時為0,所以,該block插入used鍊表的尾部,即插入頭部釋放 下面還是以《導讀》中的分組統計為例,我們再來看一下MEM_ROOT是如何釋放内存的?
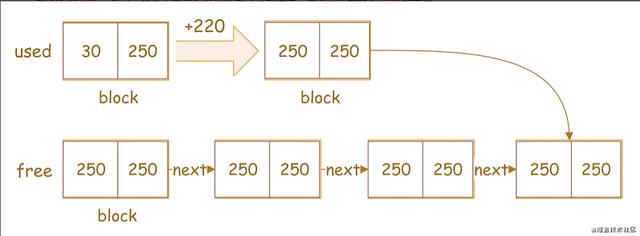
如上圖,MEM_ROOT釋放内存的過程如下:
遍曆used鍊表中,找到需要釋放的block,如上圖,block(30,250)為之前已分配給分組統計用的block将block(30,250)中的left 220,即30 220 = 250,釋放該block已使用的220大小的内存區,得到釋放後的block(250,250)将block(250,250)插入free鍊表尾部,如上圖曲線箭頭部分 通過MEM_ROOT内存分配和釋放的講解,我們發現MEM_ROOT的内存管理方式是在每個Block上連續分配,内部碎片基本在每個Block的尾部,由min_malloc成員變量控制,但是min_malloc的值是在代碼中寫死的,有點不夠靈活。所以,對一個block來說,當left小于min_malloc,從其申請的内存越大,那麼block中的left值越小,那麼,該block的内存利用率越高,碎片越少,反之,碎片越多。這個寫死是MySQL的内存分配的一個缺陷。
磁盤臨時表 當分組及統計字段對應的所有值大小超過tmp_table_size決定的值,那麼,MySQL将使用磁盤來存儲這些值。這個存放值的磁盤區域,MySQL叫它磁盤臨時表。
我們都知道磁盤存取的性能一定比内存存取的性能差很多,因為會産生磁盤IO,所以,一旦分組及統計字段不得不寫入磁盤,那性能相對是很差的,所以,我們盡量調大參數tmp_table_size,使得組及統計字段可以在内存臨時表中處理。
執行過程 無論是使用内存臨時表,還是磁盤臨時表,臨時表對組合及統計字段的處理的方式都是一樣的。《導讀》中我提到想要優化《導讀》中的那條SQL,就需要知道SQL執行的原理,所以,下面我就結合上面講解的臨時表的概念,詳細講講這條SQL的執行過程,見下圖:
創建臨時表temporary,表裡有兩個字段viewed_user_age和count(*),主鍵是viewed_user_age,如上圖,倒數第二個框temporary表示臨時表,框中包含兩個字段viewed_user_age和count(*),框内就是這兩個字段對應的值,其中viewed_user_age就是這張臨時表的主鍵掃描表輔助索引樹idx_user_viewed_user,依次取出葉子節點上的id值,即從索引樹葉子節點中取到表的主鍵id。如上圖中的idx_user_viewed_user框就是索引樹,框右側的箭頭表示取到表的主鍵id根據主鍵id到聚簇索引cluster_index的葉子節點中查找記錄,即掃描cluster_index葉子節點: (1) 得到一條記錄,然後取到記錄中的viewed_user_age字段值。如上圖,cluster_index框,框中最右邊的一列就是viewed_user_age字段的值 (2) 如果臨時表中沒有主鍵為viewed_user_age的行,就插入一條記錄 (viewed_user_age, 1)。如上圖的temporary框,其左側箭頭表示将cluster_index框中的viewed_user_age字段值寫入temporary臨時表 (3) 如果臨時表中有主鍵為viewed_user_age的行,就将viewed_user_age這一行的count(*)值加 1。如上圖的temporary框遍曆完成後,再根據字段viewed_user_age在sort_buffer中做排序,得到結果集返回給客戶端。如上圖中的最右邊的箭頭,表示将temporary框中的viewed_user_age和count(*)的值寫入sort_buffer,然後,在sort_buffer中按viewed_user_age字段進行排序 通過《導讀》中的SQL的執行過程的講解,我們發現該過程經曆了4個部分:idx_user_viewed_user、cluster_index、temporary和sort_buffer,對比上面explain的結果,其中前2個就對應結果中的Using where,temporary對應的是Using temporary,sort_buffer對應的是Using filesort。
優化方案 此時,我們有什麼辦法優化這條SQL呢?
既然這條SQL執行需要經曆4個部分,那麼,我們可不可以去掉最後兩部分呢,即去掉temporary和sort_buffer?
答案是可以的,我們隻要給SQL中的表t_user_view添加如下索引:
ALTER TABLE `t_user_view` ADD INDEX `idx_user_age_sex` (`user_id`, `viewed_user_age`, `viewed_user_sex`); 複制代碼
你可以自己嘗試一下哦!用explain康康有什麼改變!
小結 本章圍繞《導讀》中的分組統計SQL,通過explain分析SQL的執行階段,結合臨時表的結構,進一步剖析了SQL的詳細執行過程,最後,引出優化方案:新增索引,避免臨時表對分組字段的統計,及sort_buffer對分組和統計字段排序。
當然,如果實在無法避免使用臨時表,那麼,盡量調大tmp_table_size,避免使用磁盤臨時表統計分組字段。
思考題 為什麼新增了索引idx_user_age_sex可以避免臨時表對分組字段的統計,及sort_buffer對分組和統計字段排序?
提示:結合索引查找的原理。
作者:謙虛的小叮當鍊接:htt
更多精彩资讯请关注tft每日頭條,我们将持续为您更新最新资讯!





 zpostcode
zpostcode  Recruit
Recruit  weather
weather  mreligion
mreligion  Yellowpages
Yellowpages  sport
sport  constellation
constellation  shopping
shopping  name
name  game
game  directory
directory  literature
literature  Word
Word  tour
tour  furnish
furnish  Lottery
Lottery  tftnews
tftnews  lyrics
lyrics  News
News  digital
digital  car
car  dir
dir  Edu
Edu  Finance
Finance 







